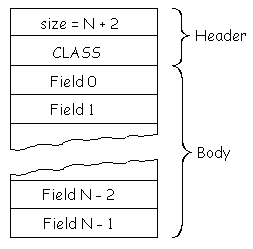
Free Space Related Constants
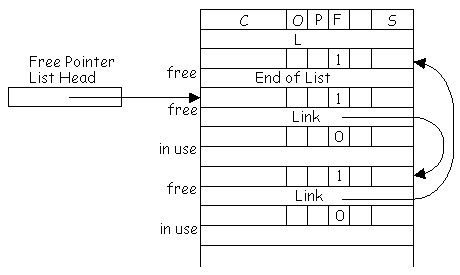
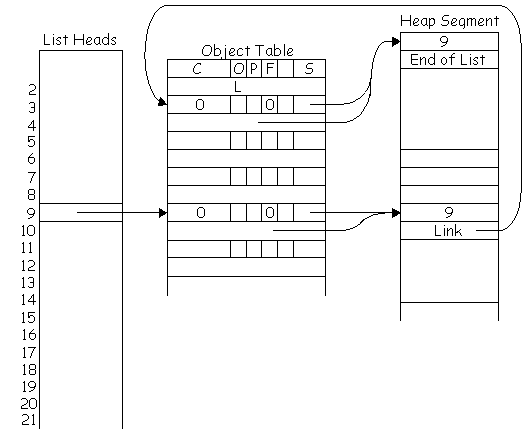
| FreePointerList |
The location of the head of the linked list of free object table entries. |
| BigSize |
The smallest size of chunk that is not stored on a list whose chunks
are the same size. (The index of the last free chunk list). |
| FirstFreeChunkList |
The location of the head of the linked list of free chunks of size
zero. Lists for chunks of larger sizes are stored in contiguous locations
following FirstFreeChunkList. Note that the lists at FirstFreeChunkList
and FirstFreeChunkList + 1 will always be empty
since all chunks are at least two words long. |
| LastFreeChunkList |
The location of the head of the linked list of free chunks of size
BigSize
or larger. |
NonPointer
|
Any sixteen-bit value that cannot be an object
table index, e.g., 216 - 1.
|
A separate set of free chunk lists is maintained for each heap segment,
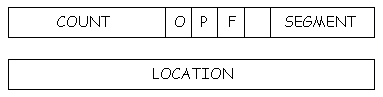
but only one free pointer list is maintained for the object table. Note
that the object table entry associated with a "free chunk" is not a "free
entry." It is not on the free pointer list, and its free entry bit is not
set. The way a free chunk is distinguished from an allocated chunk is by
setting the count field of the object table entry to zero for a free chunk
and to nonzero for an allocated chunk.